
Availability and continuity are terms that can cause confusion when used next to each other. Availability is about a part of the IT landscape, such as a service. Continuity is about the process that uses it. Availability is a precondition for continuity. For instance, the continuity of the invoicing process depends on the availability of the email service to send invoices.
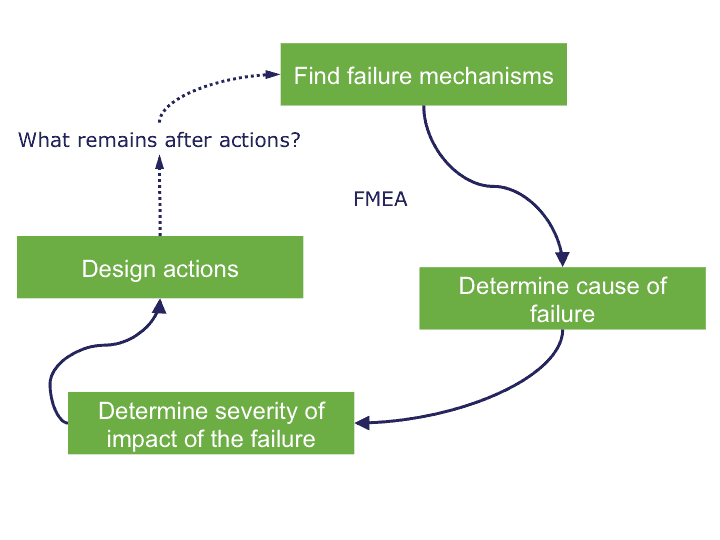
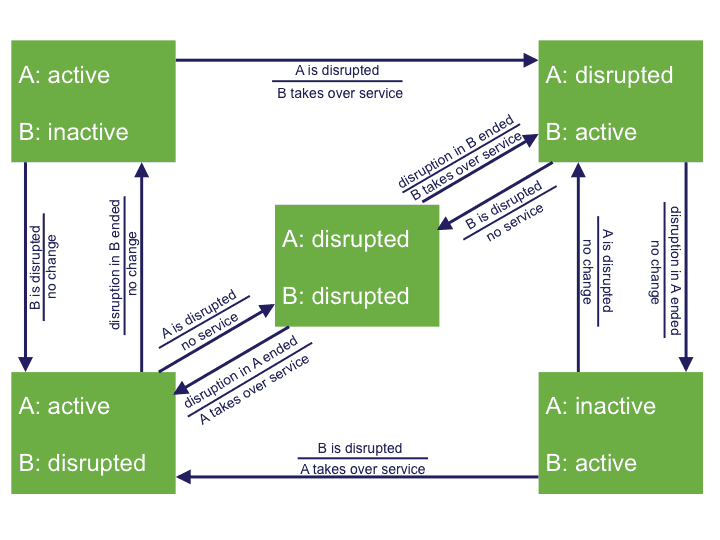
The continuity of processes is key (also known as business continuity and business reliability), and the following questions need to be answered: How often does a disruption occur, how fast is it resolved, and what damage has this disruption caused? To reach high service availability, a duplicated setup is needed so when a failure occurs, a spare part can take over the function of the failing part (failover or fallback). These mechanisms are (luckily) rarely used, so it is uncertain whether they actually work. However, the impact is large, so testing is crucial.
When there is a continuity failure, it is usually the service failure that is considered. However, the continuity of business processes can also be disrupted when a supplier alters the behavior of the service. Sometimes these can be predicted by previously announced changes.
In addition to changes in the service, other events can occur that cause continuity to be in jeopardy. In the selection and implementation stages, what-if scenarios can be worked out during risk analysis. For example, what happens to the data when a supplier or the customer goes bankrupt or when there is a business conflict? With major business risks, testing or simulating what-if scenarios is a measure to be considered.

Terug naar Testing cloud services | Terug naar Test Measures






